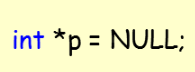package hiding;
public class Student {
public int studentID;
public String studentName;
public int grade;
public String address;
}
package hiding;
public class StudentTest {
public static void main(String[] args) {
Student student = new Student();
student.studentName="홍길동";
System.out.println(student.studentName);
}
}
그리고 두번째 예시를 보자.
getter, setter 함수를 이용해 private 멤버변수를 접근하도록 했다.
package hiding;
public class Student {
public int studentID;
private String studentName;
public int grade;
public String address;
public String getStudentName() {
return studentName;
}
public void setStudentName(String studentName) {
this.studentName = studentName;
}
}
package hiding;
public class StudentTest {
public static void main(String[] args) {
Student student = new Student();
//student.studentName="홍길동";
student.setStudentName("홍길동");
System.out.println(student.getStudentName());
}
}
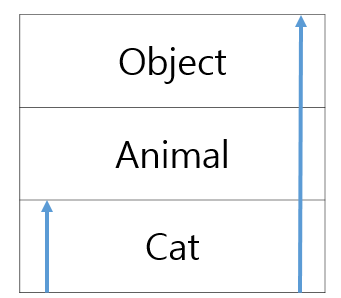
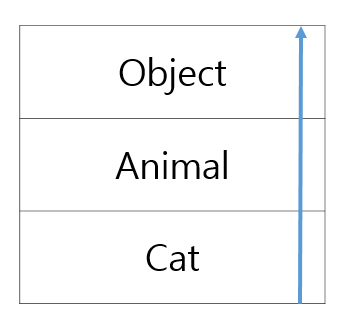
접근 제어자를 private으로 선언하면 외부 클래스에서 사용할 수 없다.
그리고 위 1, 2예시 모두 결국엔 변수를 사용할 수 있다.
그렇다면 굳이 왜 접근제어자를 private으로 써서 귀찮게 메서드를 만들어 사용하는게 바람직한걸까?
메서드에 조건문을 달아주면 오류가 나더라도 그 값이 해당 변수에 대입되지 않아 정보의 오류를 막을 수 있다
package hiding;
public class Student {
private int studentID;
public String studentName;
public int grade;
public String address;
public int getStudentID() {
return studentID;
}
public void setStudentID(int studentID) {
if(studentID >32) {
System.out.println("오류, 다시 입력하시오");
}else {
this.studentID = studentID;
}
}
}
package hiding;
public class StudentTest {
public static void main(String[] args) {
Student student = new Student();
student.setStudentID(33);
}
}
이치럼 클래스 내부에 사용할 변수나 메서드는 private으로 선언해서 외부에서 접근하지 못하도록 하는 것을 정보 은닉이라고 한다
package test;
class Book {
private String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
public void getTitle(String title){
this.title= title;
}
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
science.getTitle("안녕");
System.out.println(science.getTitle());
Book english = new Book();
english.getTitle("안녕안녕");
System.out.println(english.getTitle());
}
}
1-1) 생성자에서 다른 생성자를 호출하는 this
아래와 같이 클래스에 생성자가 여러 개 있을 때 this라는 예약어를 통해 이 클래스의 다른 생성자를 호출할 수 있다
Book()생성자에서 this("1번째 책")을 사용해 Book(String title) 생성자를 호출한 것이다
package test;
class Book {
public String title;
public int price;
public String company;
public String author;
public Book(){
this("1번째책");
}
public Book(String title){
this.title= title;
}
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
System.out.println(science.title);
}
}
1-2) 자신의 주소를 반환하는 this도 있는데 이 부분은 생략한다
2. static 변수
static 변수는 C언어에서 봤던 개념과 거의 똑같다.
프로그램이 실행되어 메모리에 올라갔을 때 딱 한번만 메모리 공간이 할당되며 그 값은 모든 인스턴스가 공유한다
아래 예문의 결과값을 예상해보자.
package test;
class Book {
public int a=2;
static public int b=3;
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
Book english = new Book();
english.a++;
System.out.println(science.a);
english.b++;
System.out.println(science.b);
science.a++;
System.out.println(english.a);
science.b++;
System.out.println(english.b);
}
}
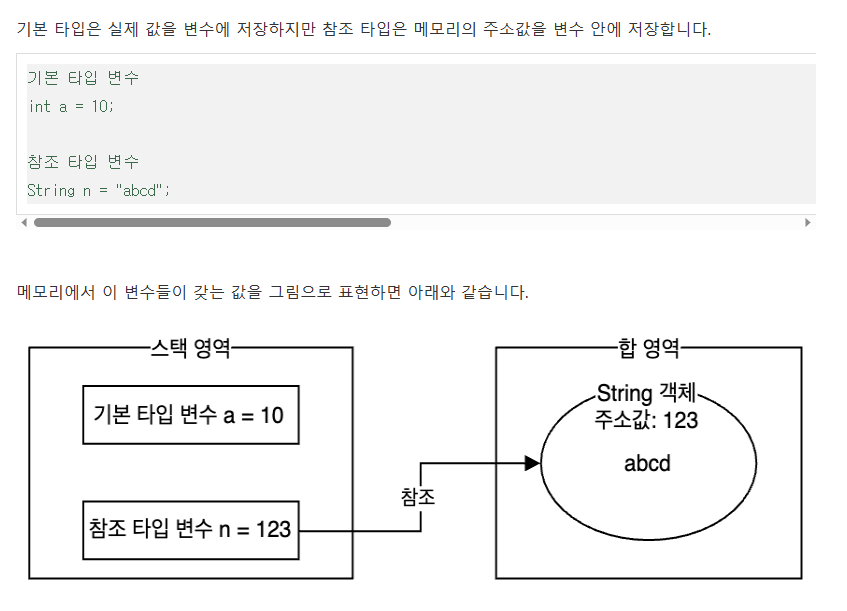
*이 게시글에서는 속성=필드=객체변수=인스턴스 변수=멤버변수라고 불리는 것을 객체 변수라고 통일하겠다.
1. 객체 생성
앞선 2탄에서 클래스, 객체, 메서드, 메모리 구조에 대해 살펴 보았다.
클래스는 책을 예를 들어 책이라는 자료형을 만들기 위해 구성요소(제목, 가격, 출판사, 저자등)를 하나로 합쳐놓은 것이다.
책이라는 객체의 구성요소를 사용하기 위해 책이라는 자료형을 클래스로 만들었다면 그 구성요소를 이용해서 다양한 책(객체)을 만들어야 하지 않겠는가
자바에서는 Book science = new Book(); 이런 형태로 객체를 만들 수 있다.
이렇게 클래스를 이용해서 만든 객체 여기서는 science를 인스턴스라고 한다.
클래스는 붕어빵 틀, 객체는 붕어빵1,2 ... 이라고 생각하면 된다
package test;
class Book {
public String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
Book english = new Book();
}
}
science앞에 붙은 Book은 int, String처럼 Book이라는 자료형이라는 표시이므로
Book자료형 science를 선언한다는 의미이다.
Book science는 int a와 동일한 형태이다
뒤에 붙은 new Book()에서 new는 새로만들어진다는 예약어이고 뒤에 나오는 Book()은 생성자(Constructor)라고 불리는 녀석이다.
Book science = new Book()은 즉 science라는 책 객체를 만든다는 의미인 것이다.
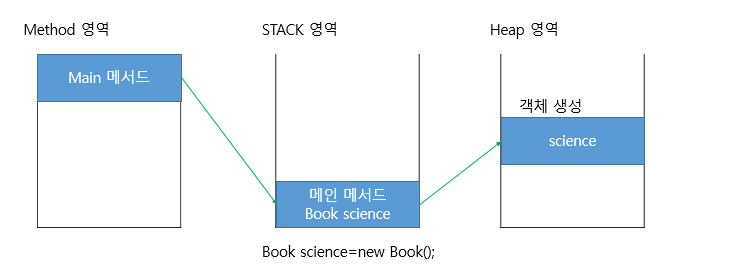
생성자얘기는 나중에 하고 우선 객체를 생성할 때 메모리에 어떻게 동작되는지 알아보자.
2. 객체 생성시 메모리 구조(heap영역)
살짝 복습하면 static이라고 붙은 메서드를 로딩하는데 거기서 제일 먼저 로딩되는 것이 main메서드이다. 위의 코드를 예를 들어 Test class의 main메서드가 제일 먼저 메모리에 로드돼서 호출된다.
호출되면 stack 영역에 들어가는데 이 메인메서드 안에는 Book science라는 변수가 선언돼있다.
이때 science라는 변수를 참조변수라고 한다.(참조변수이긴 하지만 동시에 지역변수이기도 하다)
Book science를 선언하고 new 예약어와 함께 Book()이라는 생성자를 호출하면 Heap영역이라는 메모리 공간에 science라는 객체가 하나 생성된다.
science라는 참조변수는 Heap 영역에 있는 science객체의 주소를 가리킨다.
science 객체 안에는 이런식으로 객체가 만들어져있고 science라는 참조변수는 Book객체(science)의 주소를 가리킨다.
여기서 getTitle()이라는 메서드는 실제 위치는 method 영역에 들어있지만 getName() 메서드의 주소로 메서드 영역의 getTitle()과 연결돼있다.
최종적으로 정리하면 Book science = new Book()이라고 하면 heap영역에 science객체(인스턴스)가 생성되고 science라는 참조변수는 heap영역의 science 객체(인스턴스)의 주소를 가리킨다
이렇게 객체를 생성하고 나면 그 객체의 이름인 참조변수를 이용해 객체 변수와 메서드를 사용할 수 있다
위의 예문 처럼 science.title 이렇게 도트 연산자를 이용해 각 객체의 객체변수와 메서드에 접근할 수 있게 된다
package test;
class Book {
public String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
Book english = new Book();
science.title="개미와배짱이";
System.out.println(science.title); //개미와배짱이 출력
System.out.println(science.getTitle()); //개미와배짱이 출력
}
}
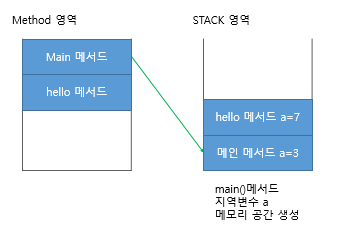
앞에서 봤던 아래 예문도 객체를 이용하면 hello메서드를 static 예약어 없이 호출가능하다
*static 포함한 경우
package test;
public class Test {
public static void main(String[] args) {
int a=3;
System.out.println(hello(a));
System.out.println(a);
}
public static int hello(int a) {
a=7;
return a;
}
}
*static을 사용하지 않은 경우
package test;
public class Test {
public static void main(String[] args) {
int a=3;
Test test1 = new Test();
System.out.println(test1.hello(a));
System.out.println(a);
}
public int hello(int a) {
a=7;
return a;
}
}
3. 생성자(Constructor)
Book science = new Book();에서
new 예약어 뒤에 붙은 Book()을 생성자라고 한다
생성자가 하는 일은 객체(인스턴스)를 heap영역에 생성하고 클래스 안에 Book() 생성자의 {}중괄호를 호출하는 역할을 하는데 객체가 생성될 때 객체 변수 값들을 초기화하는 역할도 한다
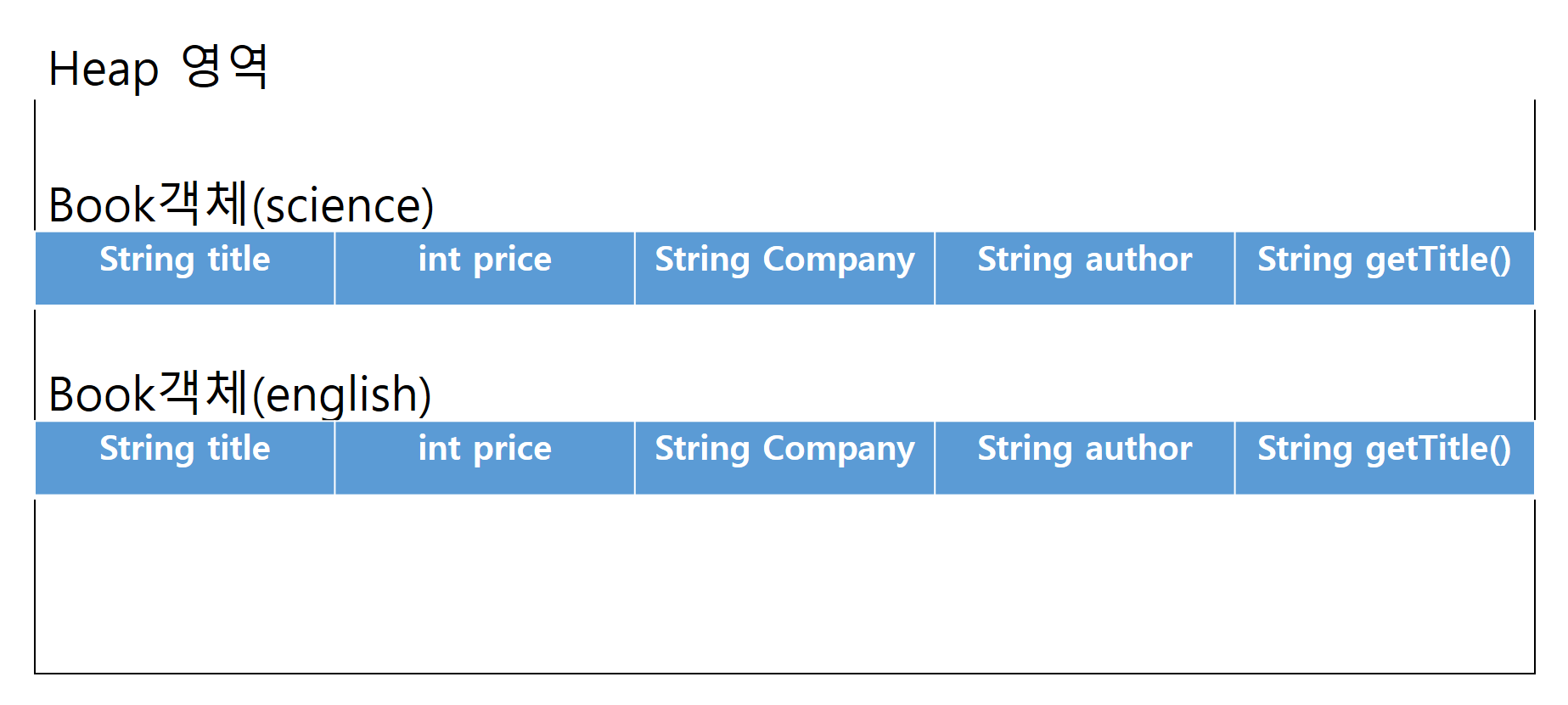
즉, science의 title과 english의 title은 다르게 설정된다는 것이다
package test;
class Book {
public String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
public Book() {} //기본 생성자
public class Test {
public static void main(String[] args) {
Book science = new Book();
Book english = new Book();
}
}
생성자는 객체를 생성할 때만 호출되는데 생성자 이름은 클래스 이름과 같고 반환값이 없다
생성자가 없는 클래스는 클래스 파일을 컴파일할 때 자바 컴파일러에서 자동으로 생성자를 만들어주는데 이렇게 자동으로 생성되는 생성자를 기본 생성자(default constructor)이라고 한다
개발자가 매개변수가 있는 생성자를 따로 만들면 자동으로 기본 생성자가 생성이 되지 않아 기본생성자를 만들어줘야 한다
아래에 public Book(String title){}이 바로 매개변수가 있는 생성자이다
이렇게 클래스에 생성자가 두 개 이상 제공되는 경우를 생성자 오버로딩이라고 한다
자바의 한 클래스 내에 이미 사용하려는 이름과 같은 이름을 가진 메소드가 있더라도 매개변수의 개수 또는 타입이 다르면, 같은 이름을 사용해서 메소드를 정의할 수 있는데 이를 오버로딩이라고 한다
아래에 나오는 this라는 예약어는 객체 자신을 가리키는 예약어인데 우선 이런게 있다고 알고 넘어가자.
아무튼 자바의 한 클래스내에 생성자가 두 개 이상이 있으면 인스턴스를 생성할 때 원하는 생성자를 골라서 만들 수 있다
package test;
class Book {
public String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
public Book() {} //기본 생성자
public Book(String title) {
this.title=title;
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
Book english = new Book();
}
}
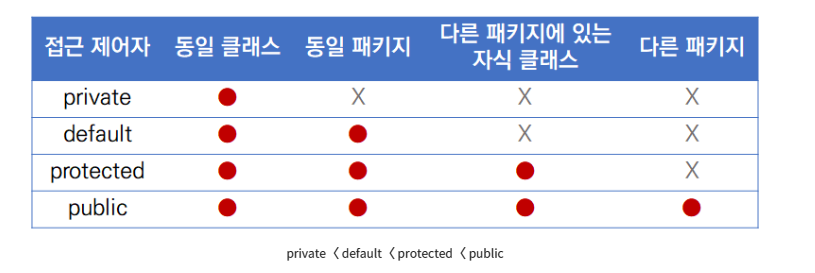
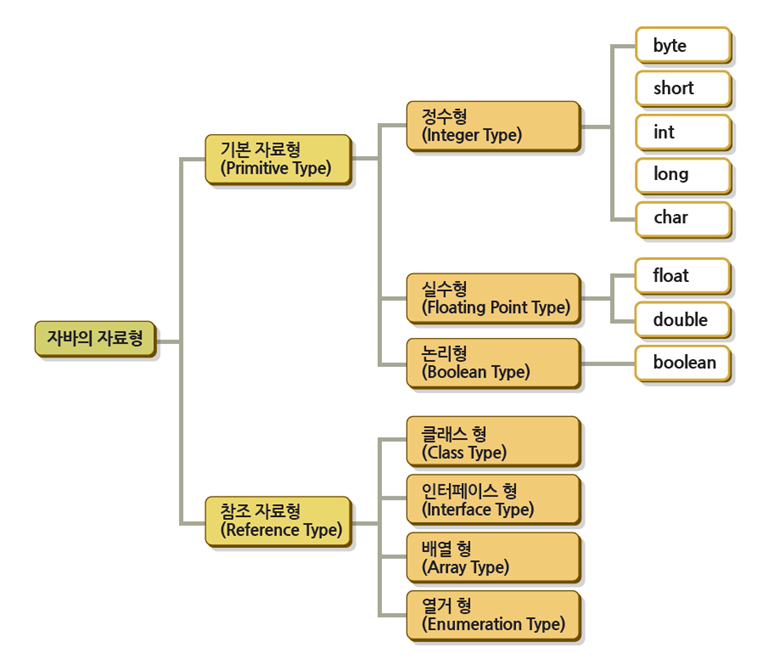
4. 접근제어자(access modifier)
자바에서는 예약어를 사용해서 클래스 내부의 변수, 메서드, 생성자에 대한 접근 권한을 지정할 수 있다.
이런 예약어를 접근 제어자라고 한다
접근제어자에는 private, protected, default, public 이렇게 4종류가 있다
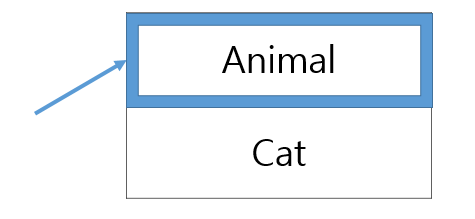
위 코드의 객체 변수 String title에 접근 제어자를 private으로 바꾸면 동일한 클래스를 제외하고는 이 변수에 직접적으로 접근할 수 없다
그래서 이를 접근하기 위해서는 메서드를 만들면 된다.
직접적으로 접근을 할 수 없으니 Book 제목을 받아오거나 지정할 수 있도록 메서드를 사용한다.
package test;
class Book {
private String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
public void getTitle(String title){
this.title= title;
}
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
//science.title="바보"; //오류발생 //접근 불가
science.getTitle("안녕");
System.out.println(science.getTitle());
}
}
정보처리기사 실기에서는 어차피 거의 대부분이 동일한 클래스로 나오므로 사실 잘 몰라도 상관없다
위의 코드는 getTitle이라는 메서드가 오버로딩돼있는 것인데
getTitle을 호출할 때 매개변수가 없으면 public String getTitle()을 호출하는 것이고
매개변수가 있으면 public void getTitle(String title)을 호출하는 것이다
각 요소들을 객체(Object)로 만든 후, 객체들을 조립해서 소프트웨어를 개발하는 기법이다. 쉽게 생각해서 컴퓨터로 예를 들면 컴퓨터의 모든 부품을 적절히 연결하고 조립해서 컴퓨터가 제대로 작동하도록 만드는 것이라고 볼 수 있다.
"학생이 밥을 먹는다"라는 예문을 생각해보자. 학생이라는 객체와 밥이라는 객체가 협력해서 문장이 구현이 된다. 객체 지향 프로그래밍도 마찬가지로 각 객체가 어떤 기능을 제공하고 객체 간 협력을 어떻게 구현할 것인지 생각해야한다.
출처 : Do it! 자바 프로그래밍 입문-박은종
2. 클래스
앞서 1탄에서 자바 프로그램은 클래스 단위이기 때문에 자바 프로그램을 만드는 것은 자바 클래스를 만드는 것과 같다고 하였다. 그렇다면 클래스는 뭘까
클래스는 공통된 연산을 갖는 객체의 집합이다
C언어에서 구조체랑 비슷하다.
C언어에서 구조체는 여러가지 자료형을 한번에 관리하기 위해 사용한 것이라면 Java에서 클래스는 여러가지 자료형과 함수(자바에서는 메서드라고 부름)를 한번에 관리하기 위해서 사용한다.
간단하게 예를 들어 생각해보자.10이라는 자료를 변수로 저장하고 싶다면 자료형을 뭘로 해야할까?int형 같은 정수형 자료형을 사용하면 될 것이다.그렇다면 책이라는 것을 변수로 저장하려면 자료형을 뭘로 해야할까?그럴때 나오는 개념이 바로 클래스이다.
책이라는 객체안에는 제목, 가격, 출판사, 저자등의 다양한 자료들이 들어가 있다.
자바에서는 아래와 같이 클래스라는 녀석을 이용해서 서로 다른 자료형들과 함수(자바에서는 메서드)를 한꺼번에 담는다.
public class Book{
public String title;
public int price;
public String company;
public String author;
}
위의 예시에서 title, price, company, author같이 클래스안에 들어있는 변수를 필드 또는 멤버변수 또는 객체변수 또는 속성 또는 인스턴스 변수라고 한다
<Book>
String title
int price
String company
String author
위와 같은 느낌으로 생성된다.
3. 메서드
클래스에 포함되는 함수를 메서드라고 한다
일단 함수는 C언어에서도 봤었다.
형태는 거의 동일하다
아래 예시에서
int는 반환값
add는 메서드 이름
int a, int b는 매개변수이다.
int add(int a,int b) {
return a+b;
}
4. 자바의 메모리 구조와 변수
아래 예문의 출력 결과를 예상해보자.
package test;
public class Test {
public static void main(String[] args) {
int a=3;
System.out.println(hello(a));
System.out.println(a);
}
public static int hello(int a) {
a=7;
return a;
}
}
// 클래스 블록
public class 클래스명 {
// 메서드 블록
public static void main(String[] args) {
System.out.println("Hello java");
}
//public이 접근제어자
//static이 정적메서드와 변수
//void가 리턴자료형
//main은 메서드명
//String[] arg는 메서드의 매개 변수
}
소스코드의 가장 바깥쪽 영역은 클래스 블록이다. 클래스명은 원하는 이름으로 지을 수 있다. 단, 클래스명은 소스파일의 이름(클래스명.java)과 동일하게 사용해야 한다.
자바 프로그램은 클래스 단위이기 때문에 자바 프로그램을 만드는 것은 자바 클래스를 만드는 것과 같다.
이제 메서드블록을 살펴보자.
1) 접근 제어자
메서드 블록 부분에서 public이라고 되어 있는 부분은 접근제어자라고 하는데 이 자리에는 public, private, protected 또는 아무것도 오지 않을 수 있는데 지금은 이런게 있다고만 알고 넘어가자.
2) 정적메서드와 변수
그 다음은 static 키워드가 올수도 있고 오지 않을 수도 있다는 의미이다. static 이라는 키워드가 붙게 되면 static 메서드가 되는데 이것도 일단 이런게 있다고 알고 넘어가자.
3) 리턴자료형
그 다음 void는 메서드가 실행된 후 리턴되는 값의 자료형을 의미한다.
리턴값이 있을 경우에는 반드시 리턴 자료형을 표기해야 하며 만약 리턴값이 없는 경우라면 void 로 표기해야 한다. 이 항목은 둘 다 생략할 수는 없고 void 또는 리턴자료형이 반드시 있어야만 한다.
4) 메서드
메서드는 클래스에 포함되는 함수를 말하며 메서드명은 원하는 이름으로 지을수 있다.
메서드 명 이후의 괄호() 안의 값들은 메서드의 입력 인자를 뜻한다.
입력 인자의 갯수는 제한이 없으며 입력 인자는 "입력자료형"+"매개변수명" 형태로 이루어 진다.
String[] args는 메서드의 매개 변수이다. String[]은 배열 자료형이란 의미이고, args는 String[]자료형에 대한 변수명이다. args라는 이름은 인수를 의미하는 arguments의 약어로 관례적인 이름이다. args 대신 다른 이름을 사용해도 상관없다.
[정보처리기사/예상문제] - 2024 정보처리기사 실기 예상 문제 모음 C언어 기출문제 모음 비전공자용 C언어 요약 1탄 비전공자용 C언어 요약 2탄(조건문, 반복문, 배열) 비전공자용 C언어 요약 3탄(함수, 포인터) 비전공자용 C언어 요약 4탄(포인터 심화, 구조체)
목차 1. 포인터와 1차원 배열 2. 포인터와 2차원 배열 3. 포인터와 문자 배열 4. 포인터와 문자열 배열 5. 함수 심화(Call by Value, Call by Reference) 6. 구조체
1. 포인터와 1차원 배열 우선 배열의 이름은 배열의 시작주소이다.
아래 예문을 보자.
#include <stdio.h>
int main() {
int array[3] = { 10,20,30 };
printf("%x %x %x \n", array, array + 0, &array[0]); //배열 0번째 요소의 주소 출력
printf("%d %d %d \n", *array, *(array + 0), *&array[0]); //배열 0번째 요소의 값 10 출력
}
*array는 array(배열 이름) 주소가 가리키는 값인 10이 출력된다 *(array+0)은 array주소에 0칸 이동한 주소가 가리키는 값인 10이 출력된다 *&가 동시에 있으면 생략이 가능하다. 즉 *&arr[0]=array[0] 따라서 역시 배열의 0번째 인덱스인 10이 출력된다
결국 array==array+0==&array[0]이라는 의미이다
다만 여기서 주의점은 int형 배열이라 요소 1개의 크기는 4바이트이고 array,array+0, &array[0]으로 출력되는 값은 동일하지만 array만 0번째 요소가 아니라 배열 전체를 가리키기 때문에 12바이트(int형이 3칸있으니 12바이트)가 된다
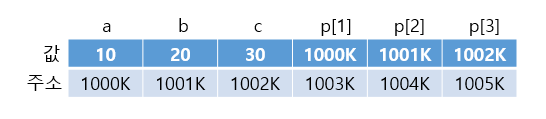
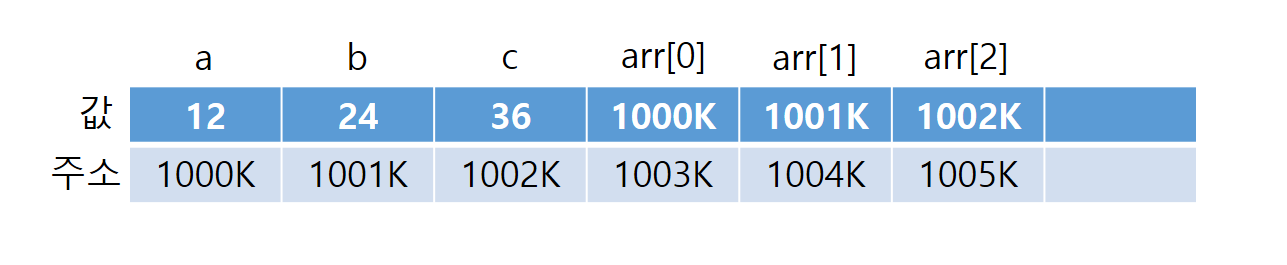
다음과 같이 포인터변수 p에 array(배열이름)으로 배열의 시작주소를 저장하면 포인터변수를 배열처럼 사용할 수 있다 아래 예문은 위의 예문과 결과값이 100% 동일하다
#include <stdio.h>
int main() {
int array[3] = { 10,20,30 };
int* p = array; //포인터 변수에 배열의 시작 주소를 저장
printf("%x %x %x \n",p,p+0,&p[0]); //배열 0번째 요소의 주소 출력
printf("%d %d %d \n", *p,*(p+0),*&p[0]); //배열 0번째 요소의 값 출력
}
다 필요없고 위 같은 경우 포인터변수 p랑 array랑 똑같다고 생각해주면 된다
2. 포인터와 2차원 배열 1차원배열에서는 *(array+i)==array[i]==*&array[i]는 값이라고 배웠는데 2차원 배열에서는 *(array+i)==array[i]==*&array[i]가 주소를 가리킨다
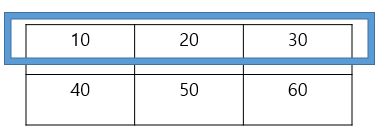
int array[2][3] = { 10,20,30,40,50,60 }라는 2차원 배열이 있을 때 테이블 같은 구조를 연상하지만 실제는 일직선으로 나란히 돼있는 것을 일단 상기시키고 가보도록 하자.
2차원배열에서도 1차원배열에서 처럼 &array[0][0] 이런식으로 하면 각 배열의 요소의 주소, *&array[0][0] 하면 각 배열의 요소의 값이 잘 출력된다.
그렇다면 아래 예문은 어떤 결과가 나올까?
#include <stdio.h>
int main() {
int array[2][3] = { 10,20,30,40,50,60 };
(1)printf("%x\n", array);
(2)printf("%x\n", array[0]);
(3)printf("%x\n", *(array + 0));
(4)printf("%x\n", &array[0][0]);
(5)printf("%x\n", array+1);
(6)printf("%x\n", array[1]);
(7)printf("%x\n", *(array + 1));
(8)printf("%x\n", &array[1][0]);
(9)printf("%d\n",sizeof(&array[0][0])); //4 출력(32비트 운영체제의 경우)
//64비트 운영체제의 경우 8로 출력된다
(10)printf("%d\n", sizeof(array[0])); //12 출력
(11)printf("%d\n", sizeof(array)); //24 출력
}
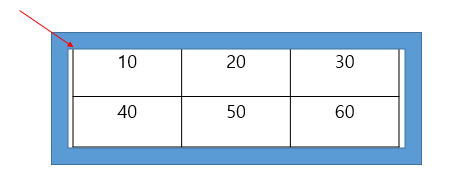
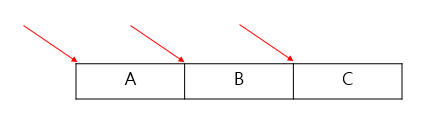
(1)~(4)까지는 array[0][0]의 주소를 출력하고 (5)~(8)까지는 array[1][0]의 주소를 출력한다
결과값은 동일하지만 4번과 8번의 경우는 arr[0][0], array[1][0] 처럼 특정한 요소의 주소를 가리키지만 나머지는 아래 그림과 같이 특정행을 가리킨다. 따라서 (9)는 특정요소를 가리키므로 4가 출력되고 (10)은 행을 가리키므로 12가 출력되고 (11)은 배열 전체를 가리켜서 24가 출력된다
*(array + 0)이 형태만 조금 더 살펴 보자 먼저 array는 배열 전체를 가리키지만 위치는 array[0][0] 시작주소에 가 있다
두번째 *(array+0)는 array에서 +0한 곳의 값을 읽는 것인데 2차원배열에서는 이 값이 행의 주소를 가리킨다 배열에서 특정 행을 가리키지만 위치는 array[0][0] 시작주소에 가 있다
세번째 array[0]+0은 배열에서 특정 행의 특정 요소 가리키지만 역시 위치는 array[0][0] 시작주소에 가 있다 따라서
모두 출력되는 값은 동일하지만 크기는 다르다 이해한 것을 토대로 아래 출력결과를 예상해보자.
하나도 이해가 안된다면 그냥 외우면된다. 1차원 배열에서는 값을 가리켰던 녀석들이 2차원 배열에서는 주소를 가리키는 것이다
1차원 배열과 동일하게 2차원 배열도 포인터를 써서 똑같이 쓸 수 있지 않을까? 생각할 수있지만 아래처럼 코드를 짜면 에러가 난다. int *p는 1차원 포인터 변수이므로 2차원 배열을 저장해도 1차원처럼 작동되기 때문이다. 따라서 이 경우에 필요한 것이 바로 배열 포인터이다.
#include <stdio.h>
int main() {
int array[2][3] = { 10,20,30,40,50,60 };
int* p = array;
printf("%d\n",p[0][0]);
return 0;
}
2-1.배열 포인터 배열 포인터는 배열을 가리키는 포인터 변수이다. 배열 포인터는 다음과 같이 선언한다.
앞에 int는 자료형이고 (*p)는 배열 포인터 변수 이름이고 [3]은 열 길이이다 이렇게 배열포인터로 선언을 하면 2차원 배열처럼 포인터도 접근할 수 있게 된다
#include <stdio.h>
int main() {
int array[2][3] = { 10,20,30,40,50,60 };
int(* p)[3] = array; //포인터 변수에 배열의 시작 주소를 저장
printf("%d\n", array[0][0]);
printf("%d\n",p[0][0]);
return 0;
}
2-2 포인터 배열 주소를 저장하는 배열
포인터 배열은 다음과 같이 선언한다
앞에 int*는 자료형이고 pointer는 포인터배열 변수 이름이고 [3]은 배열 길이이다
#include <stdio.h>
int main() {
int a = 10, b = 20, c = 30;
int* p[3] = {&a,&b,&c};
printf("%d\n", *p[0]);
printf("%d\n", *p[1]);
printf("%d\n", *p[2]);
printf("%d\n", **(p+0));
printf("%d\n", **(p+1));
printf("%d\n", **(p+2));
return 0;
}
#include <stdio.h>
int main() {
char array[4] = "ABC";
printf("%s\n", array); //ABC 출력
printf("%s\n", array+1); //BC 출력
printf("%s\n", array+2); //C 출력
return 0;
}
이런 문자열을 배열이 아니라 포인터로 바꾸면 아래와 같다
#include <stdio.h>
int main() {
char array[4] = "ABC"; //배열 방식
printf("%s\n", array);
printf("%s\n", array+1);
printf("%s\n", array+2);
char* p = "ABC"; //포인터방식
printf("%s\n", p);
printf("%s\n", p + 1);
printf("%s\n", p + 2);
return 0;
}
5. 함수 심화(Call by Value, Call by Reference)
함수에서 이때 까지 사용했던 방식이 Call my Value인데 그것은 값을 복사하는 방식이다.
#include <stdio.h>
int func(int);
int main() {
int a = 10;
printf("%d\n",func(a)); //11출력
printf("%d\n",a); //10출력
return 0;
}
int func(int a) {
a = a + 1;
return a;
}
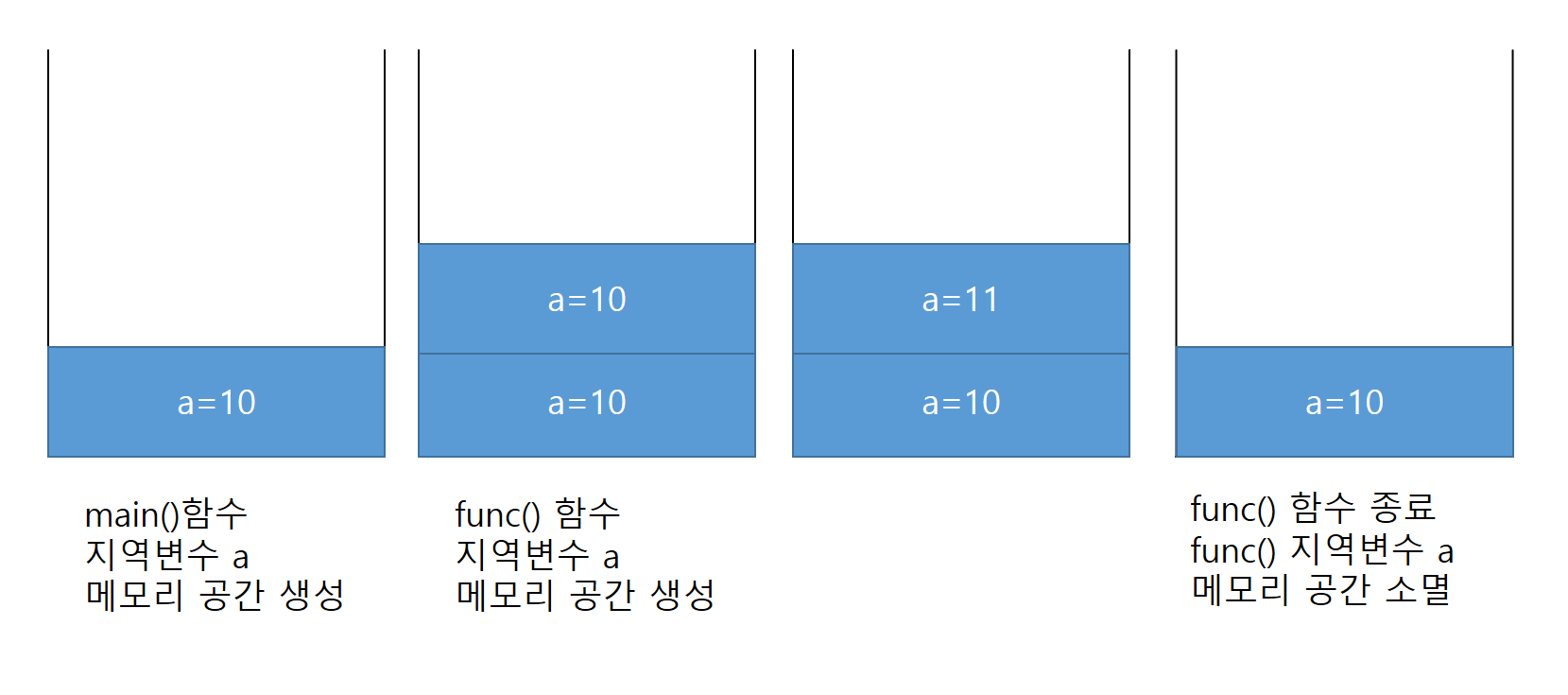
main 함수에서 변수 a를 선언하면서 초기화 한 후 a변수를 인수로 전달하면서 매개변수 a로 값이 복사된다 값을 복사하는 방식으로 main()함수의 지역변수 a 값 변동에는 영향을 미치지 않는다
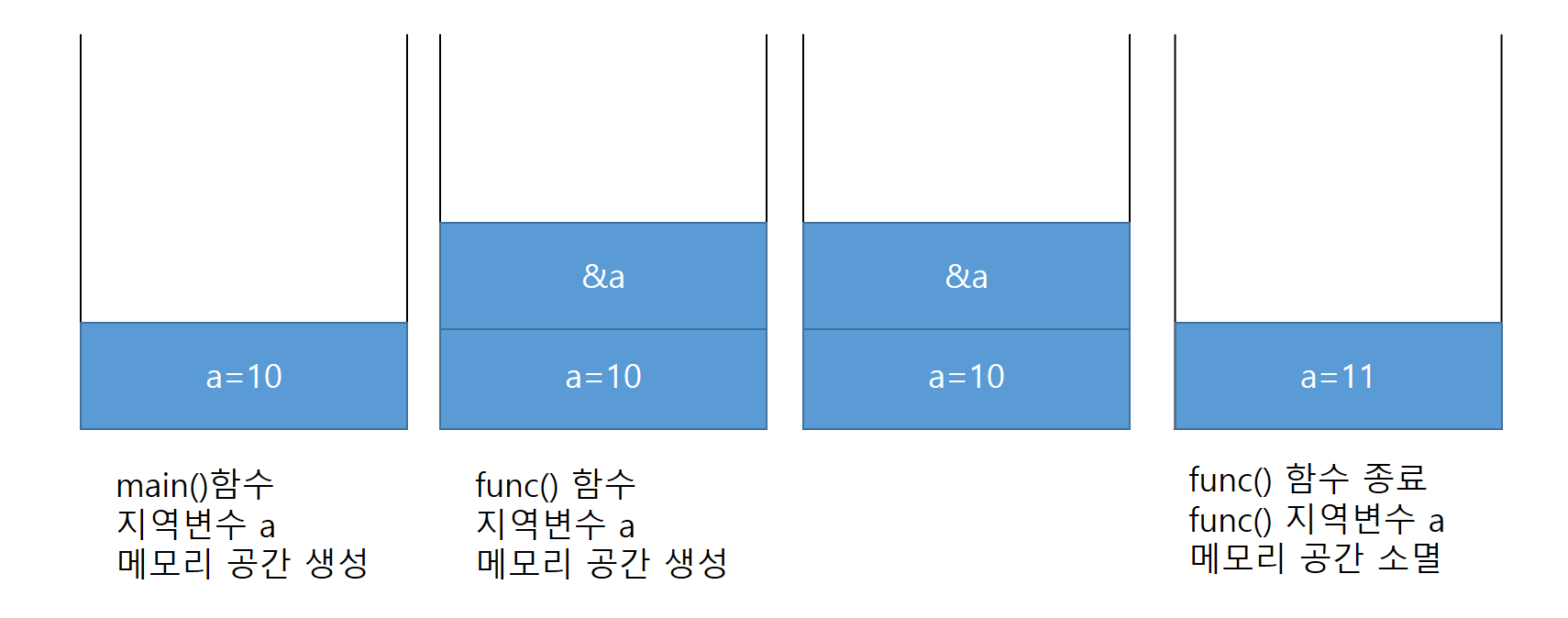
다음은 새로 배우게 될 Call by Reference(주소 참조) 방식이다 주소를 인수로 받아서 값을 바꾸기 때문에 main()함수의 지역변수 a에도 영향을 미친다
#include <stdio.h>
int func(int*);
int main() {
int a = 10;
printf("%d\n",func(&a)); //11 출력
printf("%d", a); //11 출력
return 0;
}
int func(int* a) {
*a = *a + 1;
return *a;
}
int func(int* a)인 이유는 주소를 전달받기 때문이다 쉽게 생각해서 포인터변수를 선언할 때 int *p=&a; 이런식으로 선언하는 것을 생각하면 된다 주소를 받기 때문에 함수의 매개변수 형태가 포인터변수가 되는 것이다
6. 구조체 하나 이상의 변수를 묶어 그룹화하는 사용자 정의 자료형이다 배열이 같은 자료형만 담을 수 있다면 구조체는 다른 자료형도 담을 수 있다
아래와 같은 형식으로 구조체를 정의한다 struct : 구조체 키워드 student : 구조체 이름
int score, char name은 구조체 멤버 변수
struct student
{
int score;
char name;
};
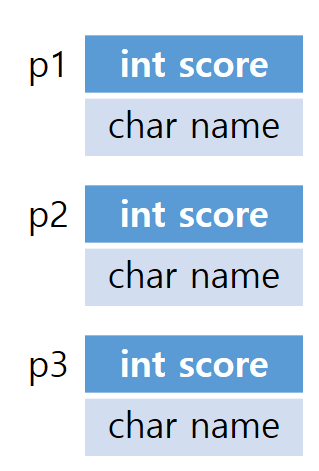
구조체 정의를 하고 구조체 변수 선언을 동시에 하는 방법은 아래와 같다.
struct student
{
int score;
char name;
}p1, p2, p3;
따로 선언하는 방식은 아래와 같다.
#include<stdio.h>
struct student
{
int score;
char name;
};
int main(){
struct student p1, p2, p3;
return 0;
}
구조체 변수에 .(도트 연산자)를 이용하면 각 변수별 멤버변수에 접근할 수 있다 p1.score이라고 하면 p1의 score에 접근이 가능해지며 p1.score=30; 이라고 하면 p1.score 자리에 30이 저장된다
#include<stdio.h>
struct p {
int* x;
int* y;
};
int main(){
int a = 5;
int b = 4;
struct p p1;
p1.x = &a;
p1.y = &b;
printf("%d %d\n", a, b);
printf("%d %d\n", *p1.x, *p1.y);
return 0;
}
함수에서 사용되는 변수는 지역 변수, 전역 변수, 정적(static) 변수, 외부(extern) 변수, 레지스터(register) 변수가 있다.
이 중에 지역 변수, 전역 변수, 정적(static) 변수만 공부해보도록 하자.
1) 지역 변수(Local Variable)
main() 함수, 조건문, 반복문의 중괄호({}) 내부와 함수의 매개 변수(Parameter)로 사용되는 변수를 의미한다
아래의 예문 출력결과가 무엇인지 예측 해보자.
#include<stdio.h>
int hello(void);
int main() {
int k = 20;
printf("%d\n",hello());
printf("%d", k);
return 0;
}
int hello(void) {
int k = 100;
return k;
}
#include<stdio.h>
int hello(void);
int main() {
int k = 20;
printf("%d\n",hello()); //100출력
printf("%d", k); //20 출력
return 0;
}
int hello(void) {
int k = 100;
return k;
}
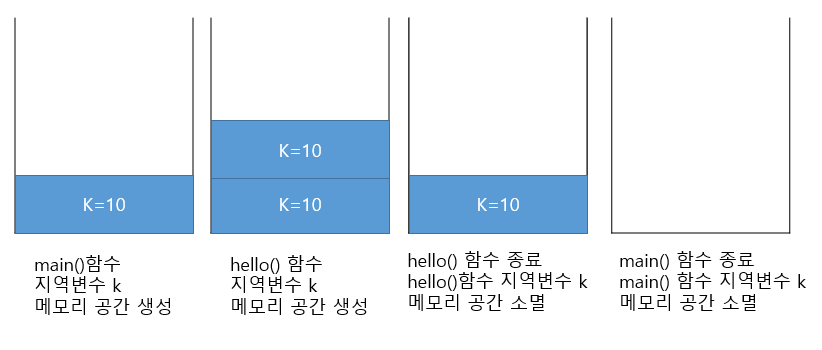
위 예문을 보면 int k=20으로 초기화를 시킨후 hello라는 함수를 호출해서 k는 100이라고 바뀐줄 알았는데 그게 아니고 20이 그대로 호출되었다.
즉, main()함수의 k와 hello()함수의 k는 다르다는 것이다.
심도있게 알기 위해서는 메모리에 대해 알아야한다.
지역변수라서 함수가 종료되면 메모리 공간이 소멸된다.
2) 전역 변수(Global Variable)
중괄호 외부에 선언되는 변수로 어느 지역에서도 사용이 제한되지 않는 프로그램 어디에서든 접근이 가능한 변수이다
중괄호가 시작되면 메모리가 생성되고 해당 중괄호에서 빠져나오면 메모리가 소멸되는 지역변수와 달리 전역변수는 프로그램이 시작되면 메모리에 생성되고 프로그램이 종료되면 메모리가 소멸된다
그래서 전역 변수는 프로그램이 종료되지 않는 한 계속해서 메모리에 존재하고 영역에 제한받지 않으며 사용된다
그리고 전역 변수는 초깃값을 지정해주지 않아도 자동으로 값을 0으로 가진다.
전역 변수의 잘못된 사용과 남용은 공유 자원에 대한 잘못된 접근으로 부작용을 낳을 수 있는데 시스템의 변경과 유지 보수를 어렵게 하는 원인이 될 수있으므로 전역 변수의 사용은 최대한 피하는 것이 바람직하다
3) 정적 변수(Static)
전역 변수의 단점을 부분적으로 보완한 변수
정적변수는 변수의 자료형 앞에 static 키워드를 넣어서 만든다
static int a;
정적 변수는 전역 변수처럼 프로그램이 종료되지 않는 한 메모리가 소멸되지 않고 초깃값을 지정하지 않아도 자동으로 0으로 가지며 또한 정적 변수는 초기화가 단 1회만 수행된다.
다음 수행결과가 무엇일지 생각해보자.
#include<stdio.h>
void hello(void);
int main() {
int k = 20;
hello();
hello();
hello();
return 0;
}
void hello(void) {
static k = 1;
int t = 0;
k++;
t++;
printf("%d %d\n", k, t);
}
static 변수 k는 한번만 초기화되므로 k가 정상적으로 계속 증가하는 것을 볼 수 있지만
지역변수 t는 계속 초기화가 진행이 돼 모든 값이 1임을 확인할 수 있다.
3. 재귀함수(Recursive Function)
함수 내에서 자기 자신을 호출하는 함수
재귀 함수의 경우 계속적인 자기 자신의 함수 호출로 시간과 메모리 공간의 효율이 저하될 수 있다.
다음 코드의 결과값을 생각해보자.
#include<stdio.h>
int fact(int);
int main() {
int a=4;
printf("%d",fact(a));
return 0;
}
int fact(int n) {
if (n <= 1)
return 1;
else
return n * fact(n-1);
}
포인터 변수의 크기는 주소를 가리키기 때문에 항상 4byte의 동일한 크기를 가진다. (32bit 운영체제 한정)
1) 주소 연산자(&) 주소 연산자는 변수의 이름 앞에 사용하여, 해당 변수의주소값을 반환한다.
2) 참조 연산자(*) 참조 연산자는 포인터의 이름이나 주소 앞에 사용하여, 포인터에 가리키는주소에 저장된 값을 반환한다.
dereference라고 하여 역참조연산자라고도 한다.
다 필요없고 포인터는 하나만 알면 된다.
*p는 선언할 때를 제외하고 무조건 값을 가리킨다고 생각하면 되고 &는 주소를 가리킨다고 생각하면 된다.
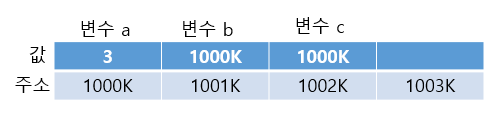
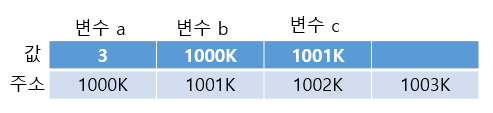
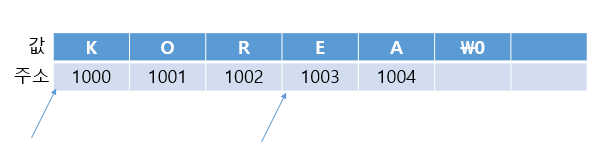
아래는 대충 이해를 돕기위해 만든 표이다. (주소는 그냥 임시로 준 값이다)
#include <stdio.h>
int main() {
int a=3;
int b=&a;
int *c=&a;
printf("%d\n",a); //그냥 변수 a를 출력
printf("%d\n",b); //b에 저장된 a의 주소의 값을 출력
printf("%d\n",c); //포인터 변수 c에 저장된 a의 주소 출력
printf("%d\n",*c); //포인터 변수 c에 저장된 a의 주소의 값 출력
return 0;
}