[정보처리기사/예상문제] - 정보처리기사 실기 예상 문제 모음
비전공자용 JAVA 요약 3탄(객체 생성, 생성자, 접근제어자)
비전공자용 JAVA 요약 4탄(this, 배열, 상속, super)
목차
1. this 예약어
2. static 변수
3. 배열
4. 상속, super 예약어
5. 오버라이딩(overrriding)
6. 추상클래스
1. this 예약어
앞에서도 맛보기로 살짝 봤듯이 this는 자기자신을 가리키는 예약어이다.
science.getTitle("안녕")이렇게 메서드를 호출하면
public void getTitle(String title){}메서드가 호출되는데
this. title= title은 즉 science.getTitle="안녕"과 동일하고
science.getTitle이라는 자기자신을 this라고 표현하는 것이다
english.getTitle("안녕안녕")도 마찬가지로
this.title=title은 english.getTitle="안녕안녕"을 뜻한다
package test;
class Book {
private String title;
public int price;
public String company;
public String author;
public String getTitle(){
return title;
}
public void getTitle(String title){
this.title= title;
}
}
public class Test {
public static void main(String[] args) {
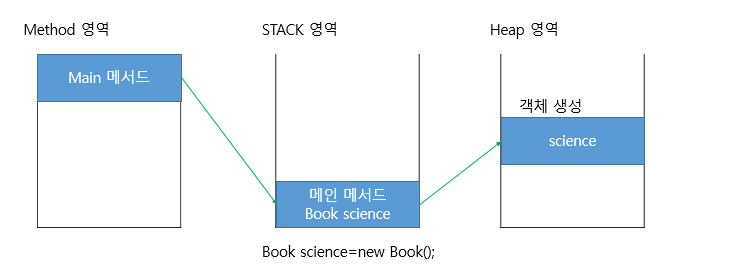
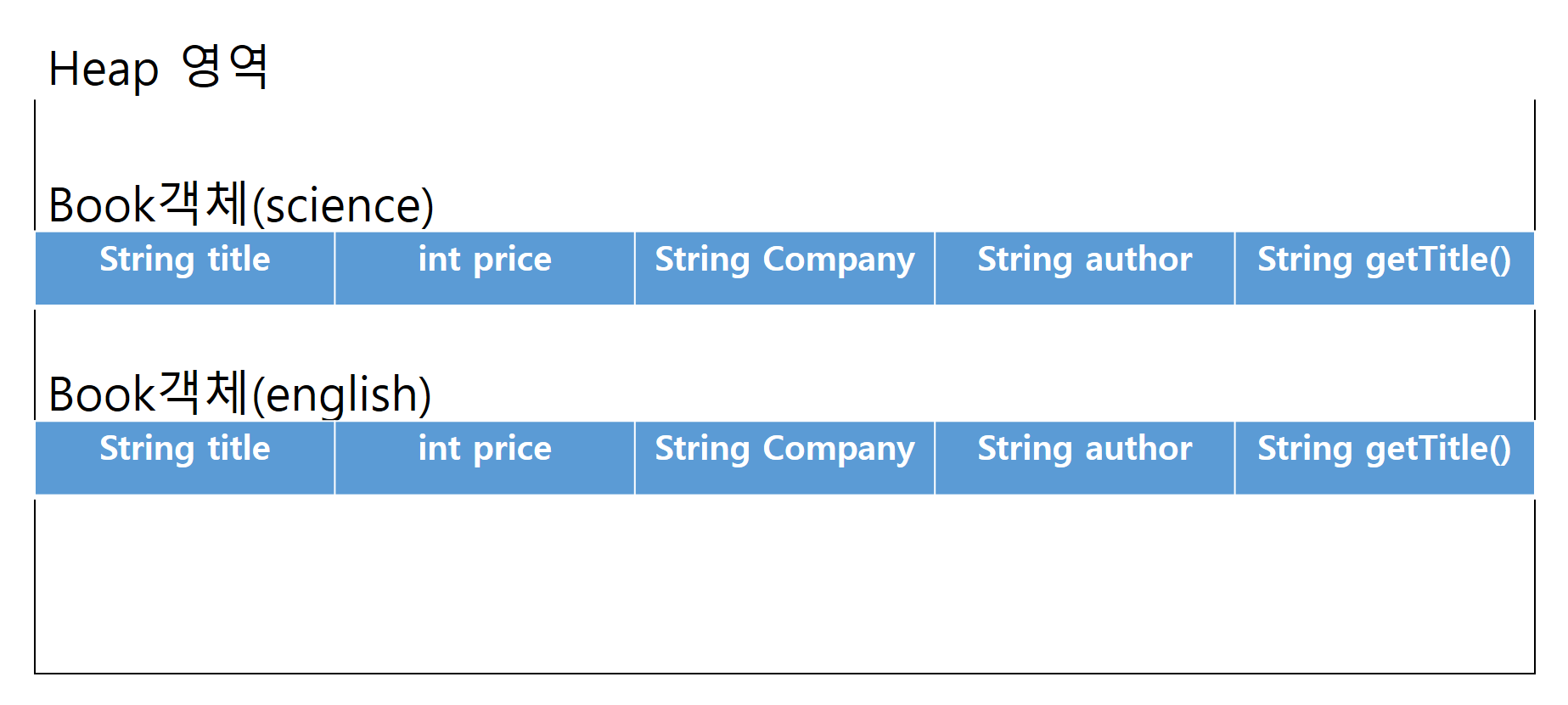
Book science = new Book();
science.getTitle("안녕");
System.out.println(science.getTitle());
Book english = new Book();
english.getTitle("안녕안녕");
System.out.println(english.getTitle());
}
}
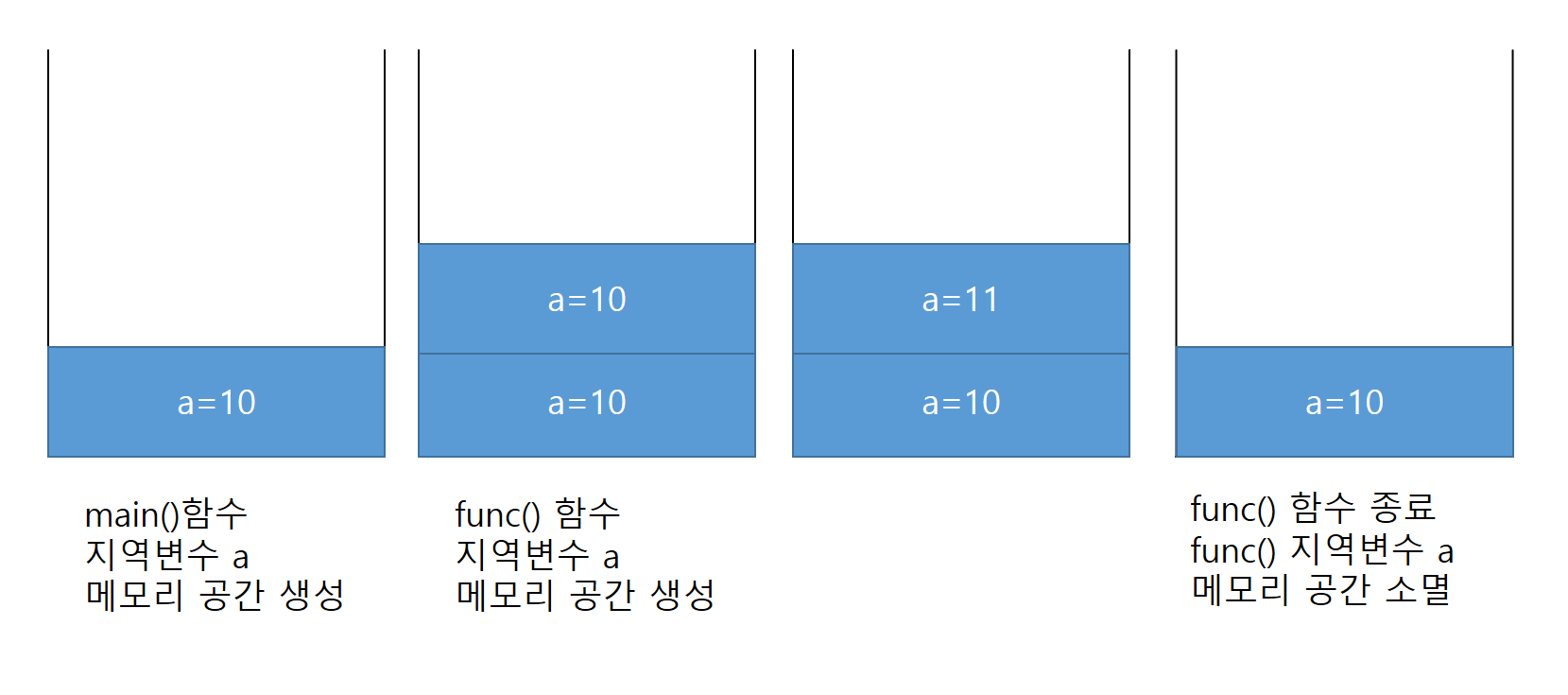
1-1) 생성자에서 다른 생성자를 호출하는 this
아래와 같이 클래스에 생성자가 여러 개 있을 때 this라는 예약어를 통해 이 클래스의 다른 생성자를 호출할 수 있다
Book()생성자에서 this("1번째 책")을 사용해 Book(String title) 생성자를 호출한 것이다
package test;
class Book {
public String title;
public int price;
public String company;
public String author;
public Book(){
this("1번째책");
}
public Book(String title){
this.title= title;
}
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
System.out.println(science.title);
}
}
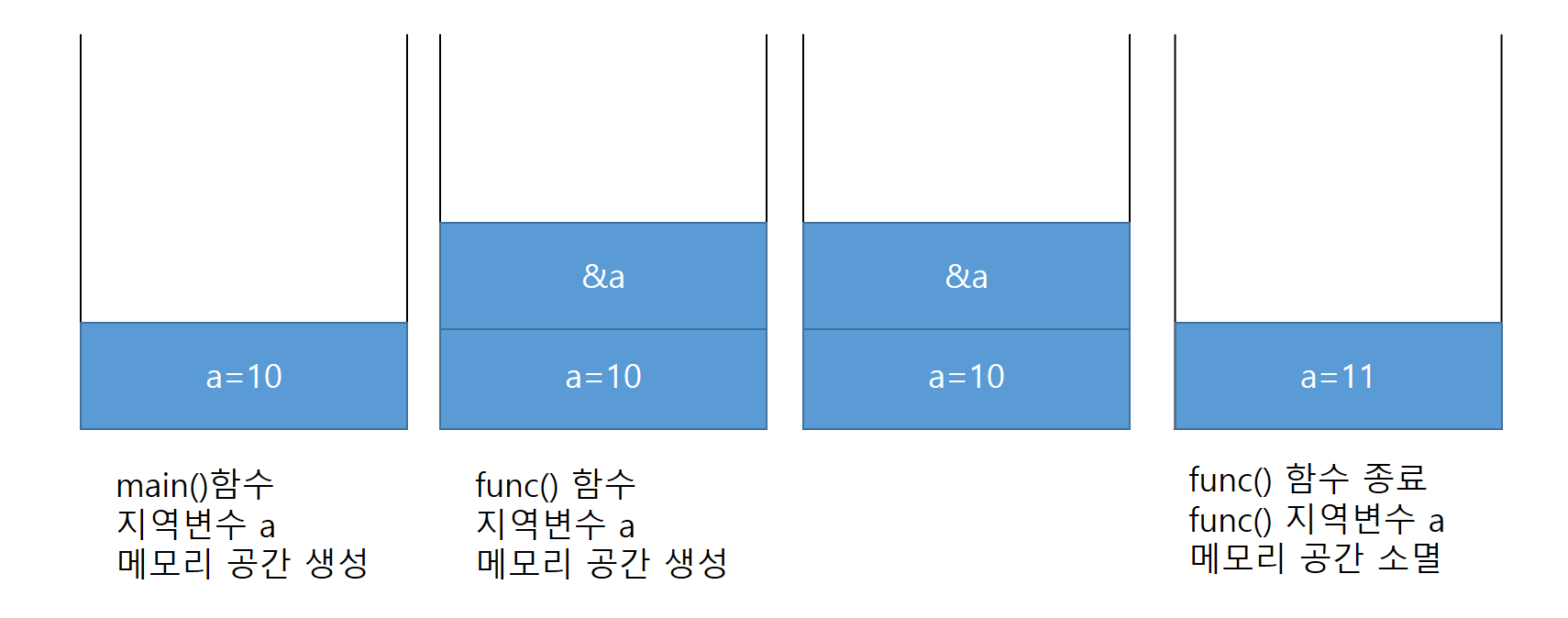
1-2) 자신의 주소를 반환하는 this도 있는데 이 부분은 생략한다
2. static 변수
static 변수는 C언어에서 봤던 개념과 거의 똑같다.
프로그램이 실행되어 메모리에 올라갔을 때 딱 한번만 메모리 공간이 할당되며 그 값은 모든 인스턴스가 공유한다
아래 예문의 결과값을 예상해보자.
package test;
class Book {
public int a=2;
static public int b=3;
}
public class Test {
public static void main(String[] args) {
Book science = new Book();
Book english = new Book();
english.a++;
System.out.println(science.a);
english.b++;
System.out.println(science.b);
science.a++;
System.out.println(english.a);
science.b++;
System.out.println(english.b);
}
}2
4
3
5
static이 아닌 a는 인스턴스마다 새로 초기화가 된다
static인 b는 맨처음 한번 3으로 초기화되고 이 3을 인스턴스끼리 공유한다
english.a++;
System.out.println(science.a); //science.a의 값은 변동이 없어 2가 된다
english.b++;
System.out.println(science.b); //b가 static변수이므로 1증가된 4가 된다
science.a++;
System.out.println(english.a); //1번증가됐으므로 1증가된 3이 된다
science.b++;
System.out.println(english.b); //b가 static 변수이므로 4에서 1증가된 5가 된다
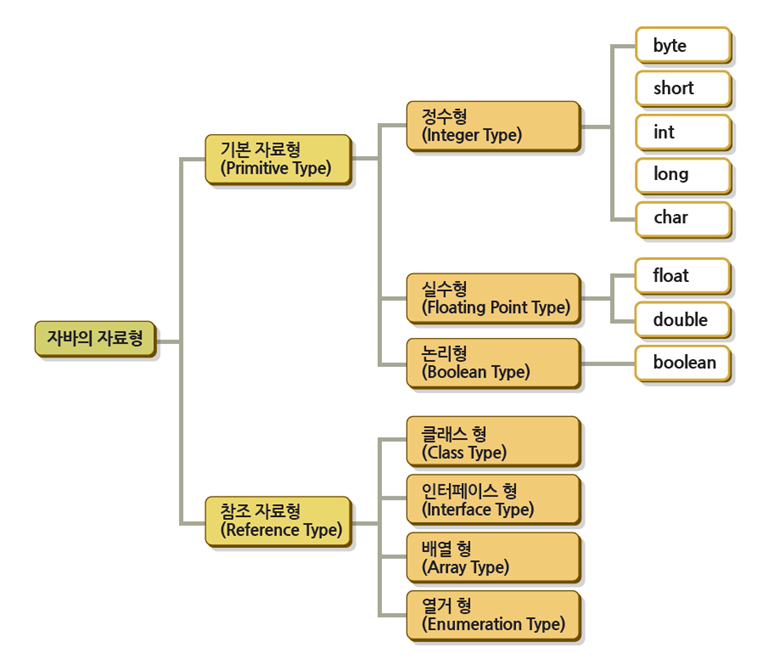
3. 배열
배열 역시 C언어에서 봤던 개념과 동일하다
클래스가 여러가지 다른 자료형을 설계하는 도구였다면 배열은 여러가지 같은 자료형을 설계하는 도구이다
배열은 같은 자료형을 여러개 한꺼번에 관리할 수 있다
배열은 아래와 같은 형태이다
| int[] a=new int[10] int a[]=new int[10] 2가지 형태가 다 가능하다 |
배열 선언과 동시에 초기화
배열은 선언하면 그와 동시에 각 요소의 값이 초기화 되며 아래와 같이 배열 선언과 동시에 특정 값으로 초기화도 가능하다
| int[] a=new int[] {1,2,3}; |
| int[] a={1,2,3}; |
자바의 배열은 배열 길이를 나타내는 length 속성을 가지며 a.length하면 3이 출력된다
package test;
public class Test {
public static void main(String[] args) {
int[] a= {1,2,3};
System.out.println(a.length);
}
}
배열의 기본적인 것들은 C언어와 동일하므로 생략한다
C언어에서의 배열 개념만 알면 자바에서 배열은 사실 문제만 풀어보면 된다
4. 상속
상속이라는 말은 익힐 들어봤을 것이다.
부모님의 재산을 물려받는 것을 보통 상속이라고 하는데 거의 똑같이 생각해주면 된다.
B 클래스가 A클래스를 상속받으면 B클래스는 A클래스의 객체 변수와 메서드를 사용할 수 있다
기본형태는 아래와 같다. Cat이라는 클래스가 Animal이라는 클래스를 상속받았고
그 표현으로 extends라는 표현을 쓴다.
package test;
class Animal {
}
public class Cat extends Animal{
}
쓸 수 있는 영역을 extends 확장한다는 것이다

상속을 하는 이유를 생각해보자.
고양이 클래스가 있고 개 클래스가 있고 하마 클래스가 있고 이런식으로 여러개의 동물 클래스가 있다고 치자.
고양이, 개, 하마를 묶어서 한꺼번에 동물이라고 표현할 수 있다
고양이, 개, 하마는 모두 동물이므로 만약 따로 따로 클래스를 만들게되면 공통된 요소들이 많아지게 될 것이다
예를 들면 eat(), sleep() 뭐 이런 것들
따로따로 만들면 기능은 똑같은데 굳이 새로 만들어줘야하므로 효율적이지 않다
그래서 상속이라는 개념을 쓴다
또한 자바에서 모든 클래스는 Object 클래스의 자식이자 하위 클래스이다.(Object가 제일 상위 클래스)
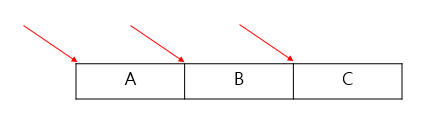
extends(상속)을 하면 아래의 그림과 같이 확장된다
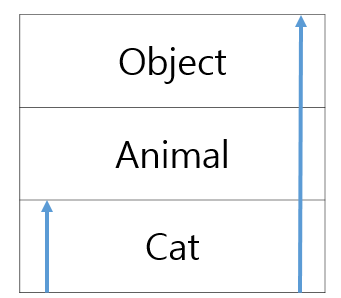
아래와 같은 예문을 보자. Cat cat1=new Cat()으로 객체를 생성하며 Cat() 생성자를 호출한다.
출력결과는 무엇일까
package test;
class Animal {
public Animal(){
System.out.println("내가 니 부모다");
}
}
public class Cat extends Animal{
public Cat(){
System.out.println("부모님 안녕하세요");
}
public static void main(String[] args) {
Cat cat1=new Cat(); //cat1 객체 생성
}
}내가 니 부모다
부모님 안녕하세요
자식 객체를 만들었는데 부모 클래스의 생성자까지 같이 호출되는 것을 확인할 수 있다
즉, 하위 클래스에서 객체가 만들어질 때는 그 객체가 만들어지기 전에 부모가 먼저 만들어지고 그 다음 자식이 만들어진다는 것이다. (생각해보면 부모가 있어야 자식이 있는 것이 당연하다)
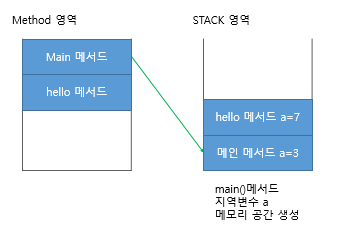
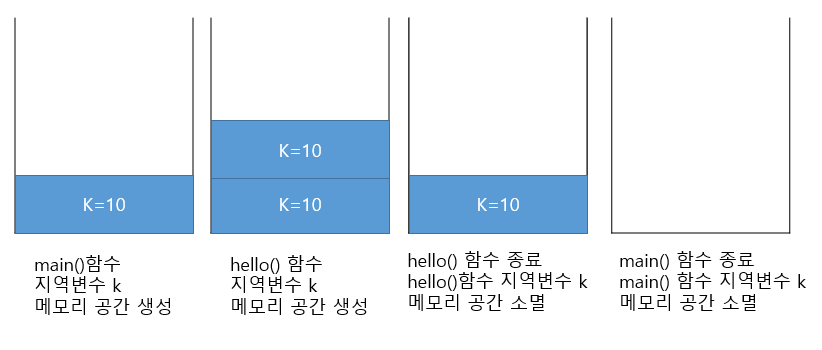
상위 클래스의 생성자가 호출된 후 상위 클래스의 객체 변수가 메모리에 생성된다
그 후 하위 클래스의 생성자가 호출된다
1) Cat cat1= new Cat(); 실행
2) Object 생성자 호출
3) Animal 생성자 호출

4) Cat 생성자 호출
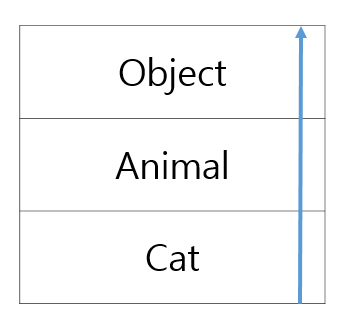
이게 가능한 이유는 원래 super()라는 예약어가 있는데 그게 생략돼있는 것이다.
super()라는 것을 생략해도 컴파일러가 자동으로 넣어준다
super 예약어는 하위 클래스에서 상위 클래스로 접근할 때 사용하며 상위 클래스의 생성자를 호출하는데도 사용한다
만약에 매개변수가 있는 상위 클래스의 생성자를 호출해야한다면 super(매개변수); 이런 형태를 쓰면 된다
5. 오버라이딩(overrriding)
아래의 출력결과를 예상해보자.
package test;
class Animal {
public void eat() {
System.out.println("동물이 밥을 먹다");
}
}
public class Cat extends Animal{
public void eat() {
System.out.println("고양이가 밥을 먹다");
}
public static void main(String[] args) {
Cat cat1=new Cat();
cat1.eat();
}
}
고양이가 밥을 먹다
객체를 생성한 후 객체의 메서드를 호출했다. 그런데 아까 배웠듯이 객체가 생성될때 부모의 생성자가 먼저 호출되며 부모가 먼저 만들어진다고 했는데 어떻게 "고양이가 밥을 먹다"가 출력 된 걸까?
이처럼 상위클래스에서 eat()메서드가 이미 정의돼있다.
그런데 상위 클래스에서 정의한 메서드가 하위 클래스에 구현할 내용과 차이가 있을 때는 하위 클래스에서 메서드를 재정의할 수 있는데 이를 메서드 오버라이딩이라고 한다
부모 메서드와 자식 메서드가 동일한 형태로 공존하지만 부모 메서드는 무시되고 자식 메서드만 실행되는 것이다
오버라이딩을 하려면 반환형, 메서드 이름, 매개 변수 개수, 매개변수 자료형이 다 같아야 한다
그렇다면 아래의 출력결과도 예상해보자.
package test;
class Animal {
public void eat() {
System.out.println("동물이 밥을 먹다");
}
}
public class Cat extends Animal{
public void eat() {
System.out.println("고양이가 밥을 먹다");
}
public static void main(String[] args) {
Animal cat1=new Cat();
cat1.eat();
}
}고양이가 밥을 먹다
이번에는 특이하게 객체를 생성하는데 객체를 생성하는 자료형과 생성자가 다르다
Animal cat1= new Cat();
객체를 생성하는 자료형은 부모 클래스인 Animal이고 생성자는 자식의 생성자이다.
부모 클래스의 객체를 생성하는 것인데 이렇게 아래 그림처럼 Animal 자료형인 cat1이 Animal만 접근하는 줄 알았는데
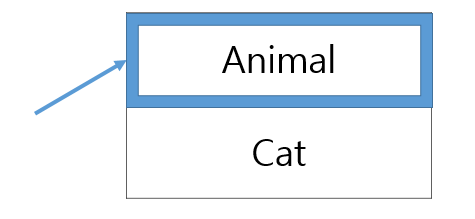
부모 클래스는 항상 자식 클래스에서 자신의 메서드를 재정의했는지 확인하기 때문에 Animal 객체를 생성했지만 Animal의 eat()메서드가 아니라 자식의 eat()메서드가 실행된다
6. 추상클래스(Abstract class)
아래의 예문을 보자.
오버라이딩이 되면서 "동물이 밥을 먹다"는 절대로 실행될 일이 없다
그렇다면 굳이 적을 필요가 있을까?
package test;
class Animal {
public void eat() {
System.out.println("동물이 밥을 먹다");
}
}
public class Cat extends Animal{
public void eat() {
System.out.println("고양이가 밥을 먹다");
}
public static void main(String[] args) {
Animal cat1=new Cat();
cat1.eat();
}
}이런 생각에서 나온 것이 바로 추상 메서드이다.
메서드에서 반환타입 메서드 이름등 이런 부분을 선언부라고 하고 안에 중괄호{} 부분을 구현부라고 하는데
아래와 같이 추상메서드는 선언부(메서드 원형)만 존재한다.

출처 : [Java의 정석]Chapter6.객체지향 프로그래밍(14~17) (velog.io)
추상메서드는 구현부가 없으므로 반드시 오버라이딩이 된다.
그리고 구현메서드도 있는데 예를 들어 Animal 클래스를 상속받은 클래스가 고양이, 개 ,하마 정도가 있다고 하면 고양이, 개, 하마는 모두 공통적으로 잠을 자므로 굳이 재정의를 하지 않고 부모 클래스의 sleep()을 그대로 쓴다.
이렇게 추상클래스는 추상메서드와 구현메서드가 있고 서로 기능이 비슷한 클래스를 말한다
이에 대비되는 개념으로는 서로 기능이 다른 클래스를 인터페이스라고 한다
인터페이스는 구현메서드가 없고 100% 추상메서드로만 구성되어있다
package test;
abstract class Animal {
public abstract void eat(); //추상메서드
public void sleep() { //구현메서드
System.out.println("밤에는 잔다");
}
}
public class Cat extends Animal{
public void eat() {
System.out.println("고양이가 밥을 먹다");
}
public static void main(String[] args) {
Animal cat1=new Cat();
cat1.eat();
cat1.sleep();
}
}
자바는 어렵게 출제가 되지 않으므로 이정도로 마무리하도록 하겠다.
이정도 공부했으면 기출문제를 풀고 개념을 다시 확인해보면 될 것이다
[정보처리기사/예상문제] - 2024 정보처리기사 실기 예상 문제 모음
비전공자용 JAVA 요약 3탄(객체 생성, 생성자, 접근제어자)
비전공자용 JAVA 요약 4탄(this, 배열, 상속, super)
'정보처리기사 > 정처기 코딩 꿀팁' 카테고리의 다른 글
| 정보처리기사 실기-비전공자용 JAVA 요약 3탄(객체 생성, 생성자, 접근제어자) (2) | 2023.05.12 |
|---|---|
| 정보처리기사 실기-비전공자용 JAVA 요약 2탄(객체지향, 클래스) (0) | 2023.05.11 |
| 정보처리기사 실기-비전공자용 Java 요약 1탄 (2) | 2023.05.10 |
| 정보처리기사 실기-비전공자용 C언어 요약 4탄(포인터 심화, 구조체) (8) | 2023.05.07 |
| 정보처리기사 실기-비전공자용 C언어 요약 3탄(함수, 포인터) (3) | 2023.05.05 |